Memory Management: the SLUB allocator
 Last time I wrote about the SLAB allocator, a method for caching objects in a pool. And then I read about SLUB, the slab allocator that is present in modern versions of the Linux kernel, and got a bit carried away with it. SLUB is brilliant due to its simplicity, and like the Linux kernel, by now I have thrown out my SLAB code in favor of SLUB. That’s how it goes with the software lifecycle; out with the old, in with the new. Descriptions of how these allocators work often either do not go into enough detail, or are way too cryptic to understand, so I’ll do my best to shed some light.
Last time I wrote about the SLAB allocator, a method for caching objects in a pool. And then I read about SLUB, the slab allocator that is present in modern versions of the Linux kernel, and got a bit carried away with it. SLUB is brilliant due to its simplicity, and like the Linux kernel, by now I have thrown out my SLAB code in favor of SLUB. That’s how it goes with the software lifecycle; out with the old, in with the new. Descriptions of how these allocators work often either do not go into enough detail, or are way too cryptic to understand, so I’ll do my best to shed some light.
Pool allocators basically cache objects of the same size in an array. Because we are talking low-level memory allocators here, the absolute size of the array is always going to be a single page. A single page is 4 kilobytes. [Yes, I know hugepages can be 2 megabytes, and sometimes even a gigabyte, but for the sake of simplicity we’ll work with regular 4k pages here].
To keep track of what array slots are in use and what slots are free, they keep a free list. The free list is just a list of indices saying which slots are free. It is metadata that has to be kept somewhere. The difference between SLAB and SLUB is the way they deal with that metadata (and boy, what a difference it makes).
In SLAB, the freelist is kept at the beginning of the memory page. The size of the freelist depends on the number of objects that can fit in the page. When the objects are small, more objects can fit into the page and the freelist will be larger than when the object size is large, not as many objects can fit in the page.
SLUB is much more clever than this. SLUB decides to keep the metadata elsewhere, and uses the full page for object storage. The result is that SLUB can do something that SLAB can not: it can store four objects of 1k each in a 4k page, or two objects of 2k, or one object of 4k in size. This is something that SLAB could never do.
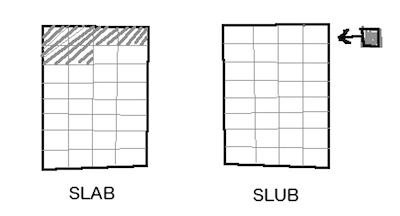
But what about the metadata? SLUB puts the free pointers inside the memory slots. The objects are free, so this memory is available for us to use.
The other metadata (like, where is the first free object? What is my object size?) is kept in a Page struct. All pages in memory are tracked by an array of Page struct. Beware the confusion here, a Page struct is not the actual memory page, it just represents the metadata for that memory page.
All we did was take that little bit of metadata from each slab, and store it elsewhere. The net result is that we can make use of memory much more effectively than before.
In our last implementation we used C++ templates to make things type safe. While this makes sense from a C++ programmer’s perspective, it doesn’t make any sense from a memory allocator’s perspective. The memory allocator has bins for sizes, not for types. This alone is reason enough not to code it using templates. Stroustrup himself said that object allocation and object creation are separate, and there’s no arguing with that.
Therefore the SLUB is implemented as a plain C code, and it turns out very straightforward and easy to understand. You have 4k of memory, the number of objects you can store equals 4k divided by object_size. The first free object slot is page_struct.free_index. When you allocate an object, return the address of slot[page_struct.free_index]. Update the free_index and zero the object’s memory, of course. And that’s all there is to it, really.
The engineers at Sun actually took into account CPU cachelines and had slab queues per CPU. This may have been a good idea in 1992 but becomes kind of crazy when you realize that today’s supercomputers comprise tens (if not hundreds) of thousands processor cores.
SLAB also needs to take into account object alignment, which is automatic in SLUB as long as the object size is a multiple of the CPU’s word size, and this is already taken care of by the compiler when it packs and pads a struct. At the end of the day, SLAB is unnecessarily complicated, over-engineered. SLUB says: Keep It Simple, Stupid!
Caches
When the slab runs out of free memory slots, you will want to get a new page and initialize it as a new slab. Likewise, when a slab is entirely free, you will want to release the page. This is trivially implemented using malloc() and free(). It’s more fun however to actually cache these pages in a linked list. The pointers for the linked list can again be members of Page struct, it’s metadata after all.
The Linux kernel optimizes for speed by keeping linked lists of full, partially full, and empty pages. When an object is allocated or freed, it always looks at the partially full list first. If after allocation the page is now full, the page is moved to the full list. If after freeing an object the page is now empty, the page is moved to the empty list.
You may wonder why it holds on to empty pages rather than releasing them immediately. The answer is that getting a new page may well take a long time. So, the empty list is an insurance policy that the cache can always quickly get a page.
If the cache is empty, it will have to get a new page from an other allocator. The Linux kernel implements the buddy allocator for managing blocks of pages. Implementing buddy allocator code is a bit complicated (and fun), I might write about that some other time.
Anyway, slab allocators are fascinating, and it’s nice to know how they work. You can’t talk about SLAB without talking about SLUB, and noting that simplicity beats complexity.